Actor Critic MM Transformer
Module: rsl_rl.modules.actor_critic_mm_transformer
🏗️ Architecture Overview
The Multi-Modal Transformer (MMTransformer) is a sophisticated neural architecture designed for humanoid robot learning that handles multi-modal observations through a BERT-style encoder design. This architecture treats humanoid observations and reference observations (expert data) as different modalities, enabling effective teacher-student distillation in the DAgger framework.
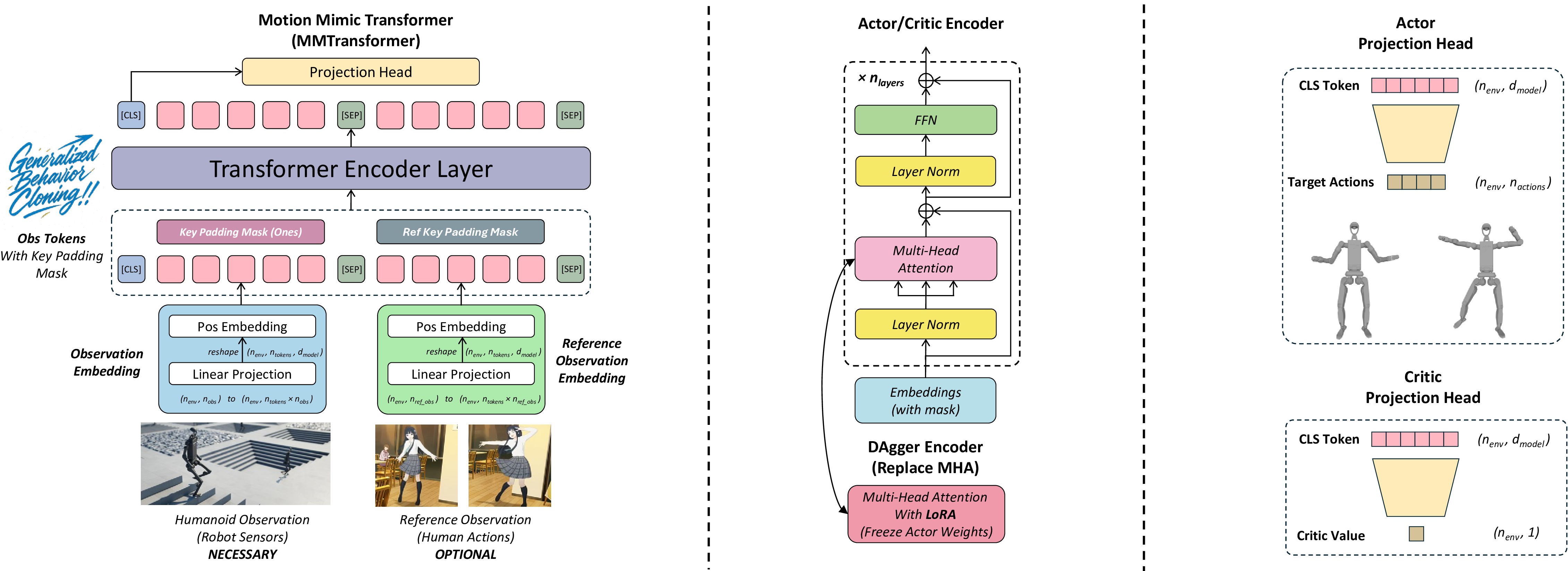
🎯 Design Principles
-
Multi-Modal Processing: The architecture separates current observations from reference (expert) observations, treating them as distinct modalities with separate embedding pathways.
-
Adaptive Masking: Reference observations are intelligently masked out in environment dimensions where reference data is no longer available, ensuring robust performance across different scenarios.
-
LoRA Integration: During DAgger step teacher-student distillation, the transformer encoder freezes its main weights and applies LoRA (Low-Rank Adaptation) for efficient fine-tuning.
-
Flexible Embedding Strategies: Multiple embedding approaches are provided to handle different observation complexities and dimensionalities.
-
Actor-Critic Architecture: The projection heads for actor and critic backbones project the CLS token to either target actions or critic values.
📊 Embedding Layer Design
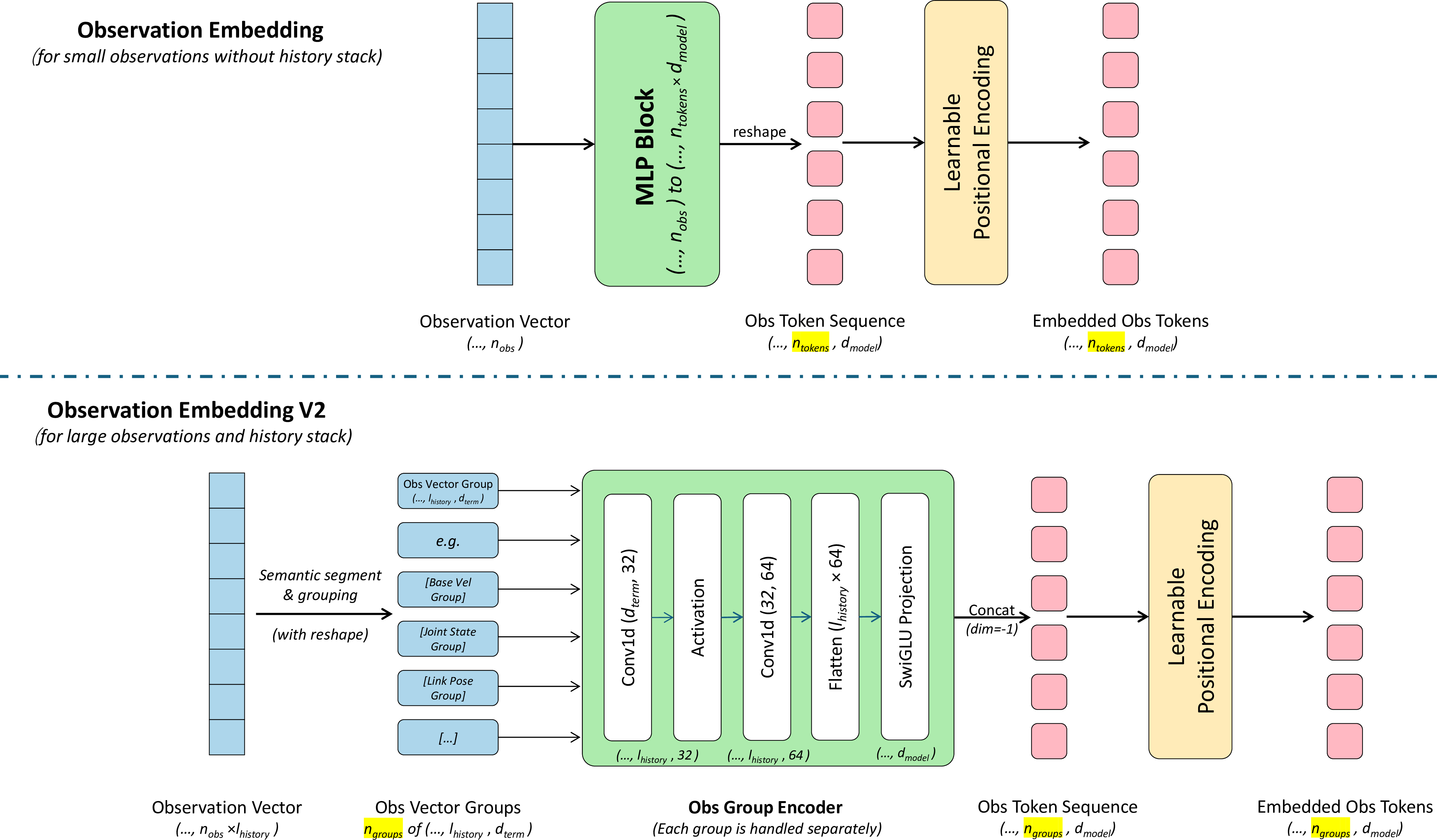
The embedding system provides multiple strategies for different use cases:
- Simple Observation Embedding: For low-dimensional observations without history stacking
- Observation Embedding V2: Advanced grouping system that categorizes observations by type (e.g., base state, joint state), handles history with convolutional layers, and uses SwiGLU projections inspired by LLaMA architecture
For detailed architectural insights and theoretical foundations, please refer to the GBC (Generalized Behavior Cloning Framework) paper.
📚 Core Components
🔧 Utility Functions
📋 group_by_concat_list
Definition:
def group_by_concat_list(orig_dict: dict, concat_list: list | None = None) -> tuple
📥 Input:
orig_dict(dict): Original dictionary mapping keys to valuesconcat_list(list | None): List of lists specifying how to group keys. Default isNone
📤 Output:
grouped_keys(list): Grouped keys by categoriesgrouped_values(list): Corresponding grouped valuesgroup_idx(list): Group indices for efficient lookup
🔧 Functionality: Groups dictionary entries based on specified concatenation patterns, enabling flexible observation grouping for the embedding layers.
🧠 Normalization and Activation
📐 RMSNorm
Module Name: rsl_rl.modules.actor_critic_mm_transformer.RMSNorm
Definition:
class RMSNorm(nn.Module):
def __init__(self, normalized_shape, eps: float = 1e-5, bias: bool = True)
📥 Parameters:
normalized_shape(int | tuple): Shape to normalize overeps(float): Small epsilon for numerical stability. Default is1e-5bias(bool): Whether to include bias term. Default isTrue
🔧 Functionality:
Root Mean Square Layer Normalization that computes y = x / sqrt(mean(x**2) + eps) * weight + bias without mean subtraction, providing more stable normalization for transformer architectures.
💡 Key Features:
- No mean subtraction (unlike LayerNorm)
- Improved numerical stability
- Compatible with modern transformer designs
🔀 SwiGLUEmbedding
Module Name: rsl_rl.modules.actor_critic_mm_transformer.SwiGLUEmbedding
Definition:
class SwiGLUEmbedding(nn.Module):
def __init__(self, input_dim: int, d_model: int, expansion_factor: int = 2)
📥 Parameters:
input_dim(int): Input dimension sized_model(int): Output model dimensionexpansion_factor(int): Hidden dimension expansion factor. Default is2
🔧 Functionality: SwiGLU activation block for embedding single observation groups, using gated linear units with Swish activation inspired by LLaMA architecture.
💡 Architecture:
input → w1 (gate) → SiLU
→ w3 (value) → multiply → w2 → output
📈 HistoryEncoder
Module Name: rsl_rl.modules.actor_critic_mm_transformer.HistoryEncoder
Definition:
class HistoryEncoder(nn.Module):
def __init__(self, history_length: int, group_per_step_dim: int, d_model: int,
use_swiglu: bool = False, swiglu_expansion_factor: int = 2)
📥 Parameters:
history_length(int): Length of history sequencegroup_per_step_dim(int): Dimension per time stepd_model(int): Output model dimensionuse_swiglu(bool): Whether to use SwiGLU projection. Default isFalseswiglu_expansion_factor(int): SwiGLU expansion factor. Default is2
🔧 Functionality: Temporal encoder for history observations using 1D convolutions for feature extraction and optional SwiGLU projection.
💡 Architecture:
input(B, T, D) → permute → Conv1D layers → flatten → SwiGLU/Linear → output(B, d_model)
🎯 Embedding Strategies
🔤 ObservationEmbedding
Module Name: rsl_rl.modules.actor_critic_mm_transformer.ObservationEmbedding
Definition:
class ObservationEmbedding(nn.Module):
def __init__(self, num_obs, d_model, max_len=16, apply_norm=False)
📥 Parameters:
num_obs(int): Number of observationsd_model(int): Model dimensionmax_len(int): Maximum sequence length. Default is16apply_norm(bool): Whether to apply RMS normalization. Default isFalse
🔧 Functionality:
Simple embedding approach that projects observations to seq_len × d_model and reshapes to transformer input format.
⚠️ Note: Simple but may amplify observation noise disturbances.
🔤 ObservationEmbeddingWithObsLen
Module Name: rsl_rl.modules.actor_critic_mm_transformer.ObservationEmbeddingWithObsLen
Definition:
class ObservationEmbeddingWithObsLen(nn.Module):
def __init__(self, num_obs, d_model, apply_norm=False)
📥 Parameters:
num_obs(int): Number of observations (treated as sequence length)d_model(int): Model dimensionapply_norm(bool): Whether to apply RMS normalization. Default isFalse
🔧 Functionality:
Treats num_obs as sequence length, giving each observation a unique positional embedding.
⚠️ Note: Simple implementation but requires significant memory.
🔤 ObservationEmbeddingV2
Module Name: rsl_rl.modules.actor_critic_mm_transformer.ObservationEmbeddingV2
Definition:
class ObservationEmbeddingV2(nn.Module):
def __init__(self, d_model: int, term_dict: dict[str, int], apply_norm: bool = False,
concatenate_term_names: list[list[str]] | None = None, history_length: int = 1)
📥 Parameters:
d_model(int): Model dimensionterm_dict(dict[str, int]): Dictionary mapping observation terms to dimensionsapply_norm(bool): Whether to apply normalization. Default isFalseconcatenate_term_names(list[list[str]] | None): Grouping specification for observation termshistory_length(int): History sequence length. Default is1
🔧 Functionality: Advanced embedding strategy that treats different observation terms as different tokens, supporting:
- Flexible observation grouping (e.g., base state, joint state)
- History handling with convolutional layers
- SwiGLU projections for intra-group modeling
- Transformer attention for inter-group relationships
💡 Features:
- Categorical Grouping: Groups related observations (velocities, joint positions, etc.)
- History Support: Uses
HistoryEncoderfor temporal sequences - Efficient Processing: SwiGLU embeddings for each group
- Positional Encoding: Term-specific positional embeddings
🤖 Transformer Architectures
🏗️ MMTransformer
Module Name: rsl_rl.modules.actor_critic_mm_transformer.MMTransformer
Definition:
class MMTransformer(nn.Module):
def __init__(self, obs_size, ref_obs_size, dim_out, dim_model, max_len=128,
num_heads=8, num_layers=4, ffn_ratio=4, dropout=0.0, name="",
ls_init_values=1e-3, apply_pooling=False, apply_mlp_residual=True, **kwargs)
📥 Parameters:
obs_size(int): Observation dimensionref_obs_size(int): Reference observation dimensiondim_out(int): Output dimensiondim_model(int): Model dimensionmax_len(int): Maximum sequence length. Default is128num_heads(int): Number of attention heads. Default is8num_layers(int): Number of transformer layers. Default is4ffn_ratio(int): Feed-forward network expansion ratio. Default is4dropout(float): Dropout probability. Default is0.0apply_pooling(bool): Whether to apply pooling. Default isFalseapply_mlp_residual(bool): Whether to apply MLP residual connection. Default isTrue
🔧 Functionality: Core multi-modal transformer that processes observations and reference observations separately with BERT-style architecture.
💡 Key Features:
- CLS/SEP Tokens: Uses classification and separation tokens
- Multi-Modal Input: Handles both current and reference observations
- Adaptive Masking: Masks unavailable reference observations
- Flexible Output: Supports both pooled and token-based outputs
🏗️ MMTransformerWithSeqLen
Module Name: rsl_rl.modules.actor_critic_mm_transformer.MMTransformerWithSeqLen
Definition:
class MMTransformerWithSeqLen(nn.Module):
def __init__(self, obs_size, ref_obs_size, dim_out, dim_model, num_heads=4,
num_layers=4, ffn_ratio=4, dropout=0.0, name="",
ls_init_values=1e-3, apply_mlp_residual=True, **kwargs)
📥 Parameters:
- Similar to
MMTransformerbut usesObservationEmbeddingWithObsLen - Always applies average pooling over non-padding tokens
🔧 Functionality: Variant of MMTransformer that treats observation dimension as sequence length, applying average pooling for final output.
🏗️ MMTransformerV2
Module Name: rsl_rl.modules.actor_critic_mm_transformer.MMTransformerV2
Definition:
class MMTransformerV2(nn.Module):
def __init__(self, dim_out, dim_model, term_dict: dict, ref_term_dict: dict | None = None,
concatenate_term_names: list[list[str]] | None = None,
concatenate_ref_term_names: list[list[str]] | None = None,
history_length: int = 1, num_heads=8, num_layers=4, ffn_ratio=4,
dropout=0.0, name="", ls_init_values=1e-3, apply_pooling=False,
apply_mlp_residual=True, **kwargs)
📥 Parameters:
term_dict(dict): Dictionary mapping observation terms to dimensionsref_term_dict(dict | None): Dictionary for reference observation termsconcatenate_term_names(list[list[str]] | None): Grouping for observation termsconcatenate_ref_term_names(list[list[str]] | None): Grouping for reference termshistory_length(int): History sequence length. Default is1- Other parameters similar to
MMTransformer
🔧 Functionality:
Advanced version using ObservationEmbeddingV2 for sophisticated observation grouping and history handling.
💡 Enhanced Features:
- Term-Based Embedding: Uses categorical observation grouping
- History Integration: Supports temporal sequence processing
- Gated Residual: Optional gated MLP residual connections
- Flexible Architecture: Supports both simple and complex observation structures
🎭 Complete Actor-Critic Systems
🎯 ActorCriticMMTransformer
Module Name: rsl_rl.modules.actor_critic_mm_transformer.ActorCriticMMTransformer
Definition:
class ActorCriticMMTransformer(nn.Module):
def __init__(self, num_actor_obs, num_actor_ref_obs, num_critic_obs, num_critic_ref_obs,
num_actions, max_len=16, dim_model=128, num_layers=4, num_heads=8,
init_noise_std=1.0, noise_std_type: str = "scalar", load_dagger=False,
load_dagger_path=None, load_actor_path=None, enable_lora=True,
dropout=0.05, **kwargs)
📥 Parameters:
num_actor_obs(int): Actor observation dimensionnum_actor_ref_obs(int): Actor reference observation dimensionnum_critic_obs(int): Critic observation dimensionnum_critic_ref_obs(int): Critic reference observation dimensionnum_actions(int): Number of actionsmax_len(int): Maximum sequence length. Default is16dim_model(int): Model dimension. Default is128num_layers(int): Number of layers. Default is4num_heads(int): Number of attention heads. Default is8init_noise_std(float): Initial noise standard deviation. Default is1.0noise_std_type(str): Type of noise standard deviation ("scalar" or "vector"). Default is"scalar"load_dagger(bool): Whether to load DAgger model. Default isFalseenable_lora(bool): Whether to enable LoRA. Default isTruedropout(float): Dropout probability. Default is0.05
🔧 Functionality: Complete actor-critic system with multi-modal transformer backbones supporting DAgger training and LoRA fine-tuning.
🎯 Key Methods
📊 Policy Methods:
def update_distribution(self, observations, ref_observations=None)
def act(self, observations, ref_observations=None, **kwargs)
def act_inference(self, observations, ref_observations=None)
def get_actions_log_prob(self, actions)
🧑🏫 DAgger Methods:
def update_distribution_dagger(self, observations, ref_observations=None)
def act_dagger(self, observations, ref_observations=None, **kwargs)
def act_dagger_inference(self, observations, ref_observations=None, **kwargs)
def get_actions_log_prob_dagger(self, actions)
💰 Critic Methods:
def evaluate(self, critic_observations, ref_critic_observations=None, **kwargs)
🔧 Utility Methods:
def load_actor_weights(self, path)
def load_dagger_weights(self, path)
def apply_dagger_lora(self, r=8, alpha=16, dropout=0.05)
def reset(self, dones=None)
🏷️ Properties:
@property
def action_mean(self) -> torch.Tensor
def action_std(self) -> torch.Tensor
def entropy(self) -> torch.Tensor
def log_std(self) -> torch.Tensor
🎯 ActorCriticMMTransformerV2
Module Name: rsl_rl.modules.actor_critic_mm_transformer.ActorCriticMMTransformerV2
Definition:
class ActorCriticMMTransformerV2(ActorCriticMMTransformer):
def __init__(self, term_dict, ref_term_dict, num_actions, history_length=1,
concatenate_term_names=None, concatenate_ref_term_names=None,
max_len=16, dim_model=128, num_layers=4, num_heads=8,
init_noise_std=1.0, noise_std_type: str = "scalar",
load_dagger=False, load_dagger_path=None, load_actor_path=None,
enable_lora=False, dropout=0.05, **kwargs)
📥 Parameters:
term_dict(dict): Dictionary mapping observation terms to dimensionsref_term_dict(dict): Dictionary for reference observation termshistory_length(int): History sequence length. Default is1concatenate_term_names(list | None): Grouping for observation termsconcatenate_ref_term_names(list | None): Grouping for reference terms- Other parameters inherit from
ActorCriticMMTransformer
🔧 Functionality:
Enhanced version using MMTransformerV2 backbones with advanced observation embedding and history handling.
🛠️ Debug and Testing Components
🔍 Debug Classes
🧠 Transformer (Debug)
class Transformer(nn.Module): # For debugging only
🧠 DebugMLP
class DebugMLP(nn.Module): # For debugging only
🎯 ActorCriticDebugMLP
class ActorCriticDebugMLP(nn.Module): # For debugging only
⚠️ Important: These classes are provided for debugging and testing purposes only. Do not use them for production PPO training.
💡 Usage Example
import torch
from rsl_rl.modules.actor_critic_mm_transformer import ActorCriticMMTransformerV2
# Define observation structure
term_dict = {
"base_lin_vel": 3,
"base_ang_vel": 3,
"joint_pos": 19,
"joint_vel": 19,
"feet_contact": 4
}
ref_term_dict = {
"ref_base_lin_vel": 3,
"ref_joint_pos": 19,
"ref_feet_contact": 4
}
# Group related observations
concatenate_term_names = [
["base_lin_vel", "base_ang_vel"], # Base state group
["joint_pos", "joint_vel"], # Joint state group
["feet_contact"] # Contact group
]
# Create actor-critic model
model = ActorCriticMMTransformerV2(
term_dict=term_dict,
ref_term_dict=ref_term_dict,
num_actions=19,
history_length=5,
concatenate_term_names=concatenate_term_names,
dim_model=256,
num_layers=6,
num_heads=8,
dropout=0.1
)
# Example forward pass
obs = torch.randn(32, sum(term_dict.values()) * 5) # Batch with history
ref_obs = torch.randn(32, sum(ref_term_dict.values()))
ref_mask = torch.ones(32, dtype=torch.bool)
# Actor forward
model.update_distribution(obs, (ref_obs, ref_mask))
actions = model.act(obs, (ref_obs, ref_mask))
# Critic forward
values = model.evaluate(obs, (ref_obs, ref_mask))
print(f"Actions shape: {actions.shape}")
print(f"Values shape: {values.shape}")
📖 References
For detailed theoretical foundations, architectural motivations, and experimental validation, please refer to:
GBC (Generalized Behavior Cloning Framework) paper, which provides comprehensive insights into:
- Multi-modal transformer design principles
- DAgger integration with LoRA fine-tuning
- Observation embedding strategies
- Empirical evaluation on humanoid robot tasks
💡 Pro Tip: The V2 variants with term dictionaries are recommended for complex robotic applications as they provide better observation organization and history handling capabilities.