Motion Mimic PPO
Module: rsl_rl.algorithms.mmppo
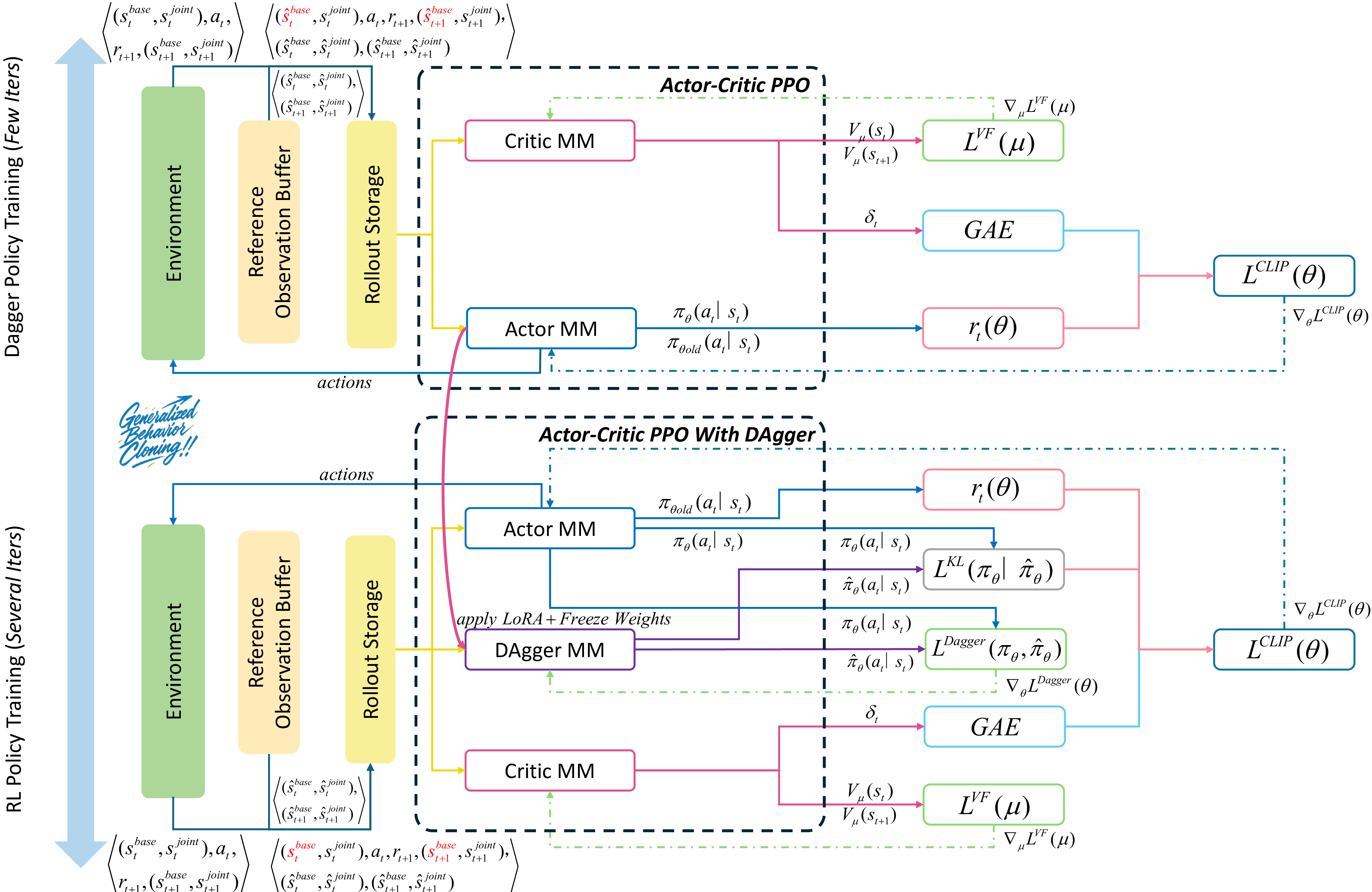
🎯 Algorithm Overview
DAgger-MMPPO (Motion Mimic Proximal Policy Optimization) is a novel two-stage reinforcement learning framework that combines the Dataset Aggregation (DAgger) algorithm with PPO training logic for whole-body humanoid robot motion learning. Unlike direct teleoperation, MMPPO enables robots to learn human-like motion patterns through behavior cloning, addressing the challenge of mapping reference motions to executable robot actions.
🏗️ Core Concepts
🎭 Two-Stage Training Framework
Stage 1: DAgger Policy Training
- Simplified physical environment with fixed robot base
- Focus on joint-level motion cloning using expert demonstrations
- Learn initial policy π_D that approximates optimal imitation policy
- State substitution: Replace agent base state with expert reference state
Stage 2: Policy Training with DAgger
- Full physical environment with task and imitation rewards
- LoRA-enhanced DAgger network for adaptive expert reference
- Dual optimization: actor improvement + DAgger network fine-tuning
- Integration with AMP and symmetry constraints
🎯 Key Innovations
- State Space Decomposition: Split robot state into base and joint components
- Reference State Mapping: Expert state substitution for ideal base control simulation
- LoRA Integration: Low-rank adaptation for efficient DAgger network fine-tuning
- Multi-Modal Learning: Support for various auxiliary learning modules (RND, AMP, Symmetry)
🧮 Mathematical Foundation
📊 MDP Formulation
The robot behavior cloning task is formulated as an MDP: (S, Ŝ, A, R, R̂, T, γ)
- S: Agent's state space
- Ŝ: Expert reference state space
- A: Agent's action space
- R(s_t, a_t, s_next): Intrinsic task reward
- R̂((s_t, ŝ_t), a_t, (s_next, ŝ_next)): Imitation reward
- T(s_next | s_t, a_t): State transition probability
- γ ∈ [0,1): Discount factor
🎯 Policy Definition
The policy is defined as:
a_t = π(o_t, ô_t) if ô_t ≠ None
a_t = π(o_t) if ô_t = None
Where:
a_t: Action at time tπ: Policy functiono_t: Current observationô_t: Reference observation (may be None)
📈 Loss Functions
Imitation Loss (KL Divergence):
L_KL(π_θ | π̂_θ) = E[s_t ~ D][-log π_θ(â_t | s_t)]
DAgger Loss:
L_DAgger(â_t_Dagg, a_t_Actor, ρ) = (1-ρ) * norm_2(â_t_Dagg - a_t_Actor)²
🧠 Core Components
📐 Loss Functions
🔧 SmoothL2Loss
Module Name: rsl_rl.algorithms.mmppo.SmoothL2Loss
Definition:
class SmoothL2Loss(nn.Module):
def __init__(self, delta: float = 1.0)
📥 Parameters:
delta(float): Threshold for switching between quadratic and linear loss. Default is1.0
🔧 Functionality: Huber loss implementation that combines L2 loss for small errors and L1 loss for large errors:
loss(x) = 0.5 * x² if |x| < delta
delta * (|x| - 0.5*delta) otherwise
🔧 L2Loss
Module Name: rsl_rl.algorithms.mmppo.L2Loss
Definition:
class L2Loss(nn.Module):
def __init__(self)
🔧 Functionality:
Standard L2 (mean squared error) loss function: loss = mean((input - target)²)
🤖 MMPPO Algorithm
Module Name: rsl_rl.algorithms.mmppo.MMPPO
Definition:
class MMPPO:
def __init__(self, actor_critic, num_learning_epochs=1, num_mini_batches=1,
clip_param=0.2, gamma=0.998, lam=0.95, value_loss_coef=1.0,
entropy_coef=0.0, learning_rate=1e-3, max_lr=1e-2, min_lr=1e-4,
# DAgger parameters
teacher_coef=None, teacher_loss_coef=None, teacher_lr=5e-4,
teacher_supervising_intervals=0, teacher_updating_intervals=0,
teacher_apply_interval=5, teacher_coef_mode="kl",
# Auxiliary modules
rnd_cfg=None, symmetry_cfg=None, amp_cfg=None,
# Training configuration
multi_gpu_cfg=None, auto_mix_precision=False, **kwargs)
📥 Core Parameters
PPO Configuration:
actor_critic(ActorCriticMMTransformer): Multi-modal actor-critic networknum_learning_epochs(int): Number of learning epochs per update. Default is1num_mini_batches(int): Number of mini-batches per epoch. Default is1clip_param(float): PPO clipping parameter. Default is0.2gamma(float): Discount factor. Default is0.998lam(float): GAE lambda parameter. Default is0.95value_loss_coef(float): Value function loss coefficient. Default is1.0entropy_coef(float): Entropy regularization coefficient. Default is0.0
Learning Rate Management:
learning_rate(float): Base learning rate. Default is1e-3max_lr(float): Maximum learning rate. Default is1e-2min_lr(float): Minimum learning rate. Default is1e-4max_lr_after_certain_epoch(float): Max LR after restriction epoch. Default is5e-3max_lr_restriction_epoch(int): Epoch to start max LR restriction. Default is25000
📥 DAgger Parameters
Core DAgger Configuration:
teacher_coef(float | None): DAgger coefficient (None disables DAgger). Default isNoneteacher_loss_coef(float | None): Imitation loss coefficient. Default isNoneteacher_lr(float): DAgger network learning rate. Default is5e-4teacher_coef_mode(str): DAgger coefficient mode ("kl", "norm", "original_kl"). Default is"kl"
Training Schedule:
teacher_supervising_intervals(int): Epochs before DAgger supervision starts. Default is0teacher_updating_intervals(int): Epochs before DAgger updates start. Default is0teacher_apply_interval(int): Interval for applying imitation loss. Default is5teacher_update_interval(int): Interval for DAgger updates. Default is1
📥 Auxiliary Module Configuration
Random Network Distillation (RND):
rnd_cfg(dict | None): RND configuration dictionary. Default isNone
Symmetry Learning:
symmetry_cfg(dict | None): Symmetry learning configuration. Default isNone
Adversarial Motion Prior (AMP):
amp_cfg(dict | None): AMP discriminator configuration. Default isNone
Distributed Training:
multi_gpu_cfg(dict | None): Multi-GPU training configuration. Default isNoneauto_mix_precision(bool): Enable automatic mixed precision. Default isFalse
🎯 Core Methods
🔄 Training Lifecycle
📊 Storage Initialization
def init_storage(self, training_type, num_envs, num_transitions_per_env,
actor_obs_shape, actor_ref_obs_shape, critic_obs_shape,
critic_ref_obs_shape, action_shape)
🔧 Function: Initializes rollout storage for experience collection with multi-modal observations.
🎭 Mode Control
def test_mode(self)
def train_mode(self)
🔧 Function: Switch between training and evaluation modes for all network components.
🚀 Action Generation
🎯 Action Selection
def act(self, obs, ref_obs, critic_obs, ref_critic_obs)
📥 Input:
obs(torch.Tensor): Current observationsref_obs(tuple): Reference observations (data, mask)critic_obs(torch.Tensor): Critic observationsref_critic_obs(tuple): Reference critic observations (data, mask)
📤 Output: Selected actions from the policy
🔧 Function: Generates actions using the actor-critic network and stores transition data including DAgger actions if enabled.
🔄 Environment Step Processing
def process_env_step(self, rewards, dones, infos)
📥 Input:
rewards(torch.Tensor): Environment rewardsdones(torch.Tensor): Episode termination flagsinfos(dict): Additional environment information
🔧 Function: Processes environment step, adds intrinsic rewards (RND, AMP), handles bootstrapping, and stores transitions.
📈 Learning Updates
🧮 Return Computation
def compute_returns(self, last_critic_obs)
📥 Input: last_critic_obs (torch.Tensor): Final critic observations for bootstrapping
🔧 Function: Computes returns and advantages using GAE (Generalized Advantage Estimation).
🔄 Main Update Loop
def update(self, epoch=0) -> dict
📥 Input: epoch (int): Current training epoch
📤 Output: Dictionary containing loss statistics
🔧 Function: Main training update including:
- PPO policy and value updates
- DAgger network fine-tuning with LoRA
- Auxiliary module updates (RND, AMP, symmetry)
- Learning rate scheduling
- Multi-GPU synchronization
🤝 Multi-GPU Support
📡 Parameter Broadcasting
def broadcast_parameters(self)
def broadcast_parameters_dagger(self)
🔧 Function: Broadcast model parameters from rank 0 to all GPUs.
🔄 Gradient Reduction
def reduce_parameters(self)
def reduce_parameters_dagger(self)
🔧 Function: Collect and average gradients across all GPUs.
🎯 Loss Computation
🔍 Imitation Loss
def _imitation_loss(self, actions_batch, obs_batch, ref_obs_batch, dagger_actions_batch)
📥 Input:
actions_batch(torch.Tensor): Actor actionsobs_batch(torch.Tensor): Observation batchref_obs_batch(tuple): Reference observation batchdagger_actions_batch(torch.Tensor): DAgger network actions
📤 Output: Imitation loss value
🔧 Function: Computes KL divergence loss between actor policy and DAgger targets using different modes:
- "kl": Standard KL divergence
- "original_kl": Original implementation KL
- "norm": L2 norm-based loss
🎓 DAgger Update
def update_dagger(self, actions_batch, obs_batch, ref_obs_batch, dagger_actions_batch)
📥 Input: Same as imitation loss 📤 Output: DAgger loss value
🔧 Function: Updates DAgger network using LoRA fine-tuning with smoothed L2 loss between DAgger predictions and teacher-student blended actions.
🎮 Training Algorithms
🎯 Stage 1: DAgger Policy Training
# Pseudocode for Stage 1
def stage1_training():
# Initialize with simplified environment (fixed base)
configure_simplified_env(fixed_base=True, prioritize_imitation=True)
for iteration in range(N_iter):
# Collect rollouts
batch = collect_rollouts(policy=pi_theta)
# State substitution: replace agent base with expert base
for transition in batch:
transition.state = (expert_base_state, agent_joint_state)
# Compute rewards (heavily weighted towards imitation)
rewards = w_R * task_reward + w_imitation * imitation_reward
# PPO update
for epoch in range(K):
update_policy_and_value(batch, mini_batches=M)
return trained_dagger_policy
🎯 Stage 2: Policy Training with DAgger
# Pseudocode for Stage 2
def stage2_training():
# Initialize actor from Stage 1, create LoRA-enhanced DAgger network
actor = initialize_from_stage1()
dagger_net = create_lora_enhanced_network(stage1_policy)
for iteration in range(N_iter):
# Collect rollouts in full environment
batch = collect_rollouts(actor, full_environment=True)
for epoch in range(K):
for mini_batch in shuffle(batch):
# Standard PPO losses
surrogate_loss = compute_ppo_loss(actor, mini_batch)
value_loss = compute_value_loss(critic, mini_batch)
# Generate DAgger actions
dagger_actions = dagger_net(observations, ref_observations)
# Imitation loss (KL divergence)
imitation_loss = compute_kl_loss(actor.distribution, dagger_actions)
# Combined actor loss
actor_loss = surrogate_loss + w_im * imitation_loss + value_loss
# Update actor and critic
update_networks(actor_loss)
# DAgger network LoRA fine-tuning
dagger_loss = (1-rho) * norm_2(dagger_actions - actor_actions)²
update_lora_parameters(dagger_loss)
# Anneal DAgger coefficient
rho = anneal_schedule(rho, iteration)
return trained_policy
🚀 Usage Example
import torch
from rsl_rl.algorithms.mmppo import MMPPO
from rsl_rl.modules.actor_critic_mm_transformer import ActorCriticMMTransformerV2
# Define observation structure
term_dict = {
"base_lin_vel": 3, "base_ang_vel": 3,
"joint_pos": 19, "joint_vel": 19,
"feet_contact": 4
}
ref_term_dict = {
"ref_base_lin_vel": 3, "ref_joint_pos": 19,
"ref_feet_contact": 4
}
# Create actor-critic model
actor_critic = ActorCriticMMTransformerV2(
term_dict=term_dict,
ref_term_dict=ref_term_dict,
num_actions=19,
history_length=5,
dim_model=256,
enable_lora=True # Enable LoRA for DAgger
)
# Configure auxiliary modules
rnd_cfg = {
"num_states": 48,
"learning_rate": 1e-3,
"reward_scale": 0.1
}
amp_cfg = {
"net_cfg": {
"backbone_input_dim": 96, # 2 * state_dim
"backbone_output_dim": 256,
"activation": "elu"
},
"learning_rate": 1e-3,
"gradient_penalty_coeff": 10.0,
"amp_update_interval": 1
}
symmetry_cfg = {
"use_data_augmentation": True,
"use_mirror_loss": True,
"data_augmentation_func": "my_module.mirror_observations"
}
# Create MMPPO algorithm
mmppo = MMPPO(
actor_critic=actor_critic,
# PPO hyperparameters
num_learning_epochs=5,
num_mini_batches=4,
clip_param=0.2,
gamma=0.99,
lam=0.95,
learning_rate=3e-4,
# DAgger configuration
teacher_coef=0.8, # DAgger coefficient
teacher_loss_coef=0.5, # Imitation loss weight
teacher_lr=1e-4, # DAgger network learning rate
teacher_coef_mode="kl", # Use KL divergence mode
teacher_apply_interval=5, # Apply imitation loss every 5 iterations
# Auxiliary modules
rnd_cfg=rnd_cfg,
amp_cfg=amp_cfg,
symmetry_cfg=symmetry_cfg,
# Training optimization
auto_mix_precision=True,
device="cuda"
)
# Initialize storage
mmppo.init_storage(
training_type="motion_mimic",
num_envs=4096,
num_transitions_per_env=24,
actor_obs_shape=(sum(term_dict.values()) * 5,), # With history
actor_ref_obs_shape=(sum(ref_term_dict.values()),),
critic_obs_shape=(sum(term_dict.values()) * 5,),
critic_ref_obs_shape=(sum(ref_term_dict.values()),),
action_shape=(19,)
)
# Training loop
for epoch in range(10000):
# Collect rollouts
for step in range(24): # num_transitions_per_env
actions = mmppo.act(obs, ref_obs, critic_obs, ref_critic_obs)
obs, rewards, dones, infos = env.step(actions)
mmppo.process_env_step(rewards, dones, infos)
# Compute returns and update
mmppo.compute_returns(final_critic_obs)
loss_dict = mmppo.update(epoch)
print(f"Epoch {epoch}:")
print(f" Surrogate Loss: {loss_dict['mean_surrogate_loss']:.4f}")
print(f" Value Loss: {loss_dict['mean_value_loss']:.4f}")
print(f" Imitation Loss: {loss_dict['mean_imitation_loss']:.4f}")
print(f" DAgger Loss: {loss_dict['mean_dagger_loss']:.4f}")
if 'mean_amp_loss' in loss_dict:
print(f" AMP Loss: {loss_dict['mean_amp_loss']:.4f}")
🎯 Key Features
🔧 Auxiliary Learning Modules
Random Network Distillation (RND):
- Intrinsic motivation through prediction error
- Encourages exploration in sparse reward environments
- Configurable reward scaling and update frequency
Adversarial Motion Prior (AMP):
- Style-based motion learning through discriminator
- Automatic motion quality assessment
- Gradient penalty for training stability
Symmetry Learning:
- Data augmentation with mirrored observations
- Mirror loss for consistent symmetric behaviors
- Automatic handling of symmetric robot configurations
🚀 Performance Optimizations
Mixed Precision Training:
- Automatic mixed precision for faster training
- Gradient scaling for numerical stability
- Memory efficiency improvements
Multi-GPU Support:
- Distributed training across multiple GPUs
- Gradient synchronization and parameter broadcasting
- Scalable to large-scale robot learning
Memory Management:
- GPU memory monitoring and optimization
- Efficient batch processing and storage
- Automatic garbage collection integration
🔧 Implementation Notes
⚠️ Important Considerations
Stage Transition:
- Stage 1 focuses on imitation with simplified physics
- Stage 2 introduces full environment complexity
- Proper initialization crucial for stable training
Hyperparameter Tuning:
teacher_coef: Start with 0.5-0.8, anneal graduallyteacher_loss_coef: 0.1-0.5 depending on task complexityteacher_apply_interval: 5-10 for stable training
DAgger Network:
- LoRA rank typically 8-16 for efficiency
- Alpha parameter 16-32 for adaptation strength
- Regular LoRA updates prevent overfitting
🚨 Common Issues
Training Instability:
- Monitor DAgger coefficient annealing schedule
- Ensure proper gradient clipping (max_grad_norm=1.0)
- Check for proper learning rate scheduling
Memory Issues:
- Use auto_mix_precision=True for large models
- Adjust num_mini_batches based on GPU memory
- Monitor GPU memory usage with built-in debugging
Convergence Problems:
- Verify expert data quality and coverage
- Check state normalization consistency
- Ensure proper reward balancing between task and imitation
📖 References
Original Research:
MMPPO: Multi-Modal Proximal Policy Optimization for whole-body humanoid robot learning with expert demonstrations and multi-modal observations.
Key Algorithms:
- PPO: Proximal Policy Optimization for stable on-policy learning
- DAgger: Dataset Aggregation for expert-guided policy learning
- LoRA: Low-Rank Adaptation for efficient network fine-tuning
- GAE: Generalized Advantage Estimation for variance reduction
Related Methods:
- AMP: Adversarial Motion Priors for stylized motion learning
- RND: Random Network Distillation for exploration
- Symmetry Learning: Data augmentation for symmetric behaviors
💡 Best Practice: Start with Stage 1 training in simplified environment, then gradually transition to Stage 2 with full physics. Monitor both imitation and task performance throughout training.